V prvním případě jsme použili gradientní algoritmus. Učená síť měla 50 jednotek, které měly adaptovatelné všechny parametry, včetně šířek a matic vah.
Výpočet jsme nechali běžet 10 000 iterací, hodnotu chybové funkce jsme zjišťovali po každé sté iteraci. Průměrný čas potřebný k provedení 100 iterací byl 101.5 s.
Experiment jsme provedli desetkrát. V prvních pěti případech jsme použili náhodné rozmístění středů a náhodné hodnoty vah blízké nule, náhodné hodnoty šířek blízké jedné a náhodné hodnoty matic vah blízké jednotkovým maticím. Dalších pět případů použilo jako středy náhodné vzorky z tréninkové množiny, nulové váhy, jednotkové šířky a matice vah. Druhá možnost nastavení vznikla během ladění a osvědčila se u některých testovacích úloh. V tomto případě dopadly obě skupiny zhruba stejně.
Obrázek 7.1 zobrazuje pokles chybové funkce během prvních 5 000 iterací. Zobrazen je průměr, minimum a maximum chybové funkce v provedených výpočtech.
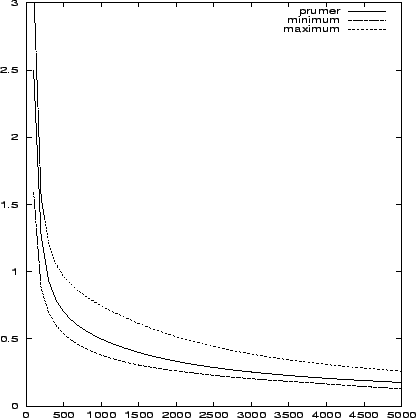 |
Během dalších 5 000 iterací je pokles chyby daleko pomalejší. Hodnoty jsou shrnuty v tabulce 7.1.
V tabulce 7.2 je uveden počet iterací potřebných k poklesu
chybové funkce pod dané ![]() .
.
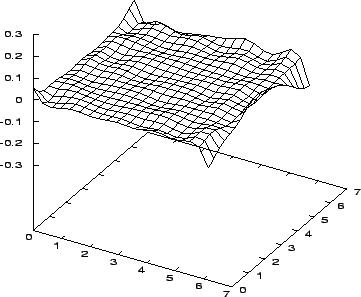
Gradientní algoritmus si s úlohou poradil. Funkce naučené sítě je na obrázku 7.2, průběh její chybové funkce na vstupním prostoru je znázorněn na obrázku 7.3.