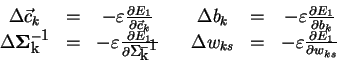
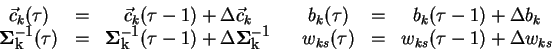
Algoritmus 3.1.1 představuje tzv. akumulované učení, kdy
k adaptaci dochází po celém průchodu tréninkovou množinou. Hodnota chybové funkce
závisí na všech tréninkových vzorech a k výpočtu hodnoty jejích derivací
potřebujeme projít celou tréninkovou množinu. Nahradíme-li funkci ![]() parciální chybovou funkcí
parciální chybovou funkcí
![]() , jejíž hodnota závisí pouze na
tréninkovém vzoru
, jejíž hodnota závisí pouze na
tréninkovém vzoru ![]() , můžeme adaptaci provádět po každém
předložení tréninkového vzoru a snížíme nároky na paměť. Tento algoritmus však
už neminimalizuje původní chybovou funkci a může zpomalovat konvergenci.
, můžeme adaptaci provádět po každém
předložení tréninkového vzoru a snížíme nároky na paměť. Tento algoritmus však
už neminimalizuje původní chybovou funkci a může zpomalovat konvergenci.