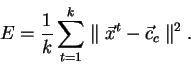V praxi se často dává přednost rychlým jednoduchým metodám před časově náročným
hledáním optimálního řešení. Osvědčilo se rovnoměrné rozmístění středů po
vstupním prostoru, výhodné zejména v případě, kdy vstupní data jsou také
rozmístěna rovnoměrně. Další možností je náhodné vybrání ![]() tréninkových
vzorů.
tréninkových
vzorů.
Pokud hledáme takové rozmístění, které opravdu zachycuje rozložení vzorů z tréninkové množiny, použijeme některý z algoritmů vektrové kvantizace.
Problém vektorové kvantizace vznikl v souvislosti se zpracováním a
aproximací signálů. Úkolem je aproximovat hustotu výskytu reálných vstupních
vektorů pomocí konečného počtu reprezentantů
![]() . Každému vektoru
. Každému vektoru
![]() pak přísluší reprezentant
pak přísluší reprezentant
![]() , který je mu nejblíže:
, který je mu nejblíže:
Kvalita řešení je dána chybovou funkcí
| (4.2) |
Metody vektorové kvantizace se snaží minimalizovat tuto funkci. Vzhledem
k tomu, že index ![]() závisí jak na vzorech
závisí jak na vzorech ![]() tak na jednotkách
tak na jednotkách ![]() ,
není triviální vyjádřit derivaci chyby vzhledem k vektorům
,
není triviální vyjádřit derivaci chyby vzhledem k vektorům ![]() . Obvyklé
gradientní metody proto nejsou vhodné a používají se různé heuristické
iterativní algoritmy.
. Obvyklé
gradientní metody proto nejsou vhodné a používají se různé heuristické
iterativní algoritmy.