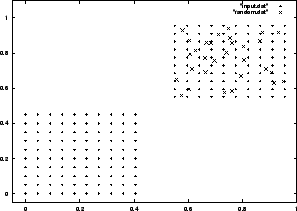
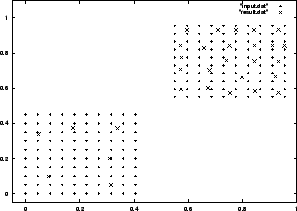
Výše uvedené algoritmy však řeší problém vektorové kvantizace jen tehdy, jsou-li vstupní hodnoty rozmístěny víceméně rovnoměrně v jedné konvexní oblasti. Podívejme se na obrázek 4.1.2. Vstupní data se vyskytují ve dvou čtercových oblastech, reprezentanty jsme při inicializaci umístili pouze do horní oblasti. Algoritmus 4.1.2 najde řešení zobrazené na obrázku 4.1.2. Jakmile je do dolní oblasti přitaženo několik nejbližších reprezentantů z horní oblasti, tito reprezentanti vyhrají všechny kompetice pro vstupy z dolní oblasti. To znamená, že žádný další reprezentat sem nebude přesunut. V nejhorším případě se může stát, že se v datech vyskytne oblast s pouze jedním reprezentantem, ačkoliv hustota výskytu vzorů v této oblasti může být vysoká.
K odstranění tohoto problému se používají různé heuristiky. Jednou z nich je
tzv. radiální růst. Začneme s reprezentanty blízkými nule a tréninkovou
množinou
![]() kde
kde ![]() je
původní tréninková množina a
je
původní tréninková množina a ![]() je parametr blízký nule. Na začátku učení
jsou tedy všechny vzory blízké všem reprezentantům. V průběhu učení zvyšujeme
číslo
je parametr blízký nule. Na začátku učení
jsou tedy všechny vzory blízké všem reprezentantům. V průběhu učení zvyšujeme
číslo ![]() a nakonec učíme původní data. Toto řešení je však časově náročné.
Další řešení navržené Desienem(1988) je tzv. metoda lokální paměti.
Vychází z předpokladu, že každý reprezentant by při stejné pravděpodobnosti měl
zvítězit zhruba
a nakonec učíme původní data. Toto řešení je však časově náročné.
Další řešení navržené Desienem(1988) je tzv. metoda lokální paměti.
Vychází z předpokladu, že každý reprezentant by při stejné pravděpodobnosti měl
zvítězit zhruba ![]() -krát. Je-li tedy četnost výher nějakého reprezentanta
příliš vysoká, vyřadíme ho na nějakou dobu ze soutěže. V samoorganizační síti
Kohonenova učení přiřadíme každému neuronu dva parametry, relativní četnost
výher
-krát. Je-li tedy četnost výher nějakého reprezentanta
příliš vysoká, vyřadíme ho na nějakou dobu ze soutěže. V samoorganizační síti
Kohonenova učení přiřadíme každému neuronu dva parametry, relativní četnost
výher ![]() a práh
a práh ![]() . Učení pak probíhá tak, že po předložení tréninkového
vzoru
. Učení pak probíhá tak, že po předložení tréninkového
vzoru ![]() určíme vítězný neuron
určíme vítězný neuron ![]() a upravíme parametry
a upravíme parametry ![]() a
a ![]() podle vzorce:
podle vzorce:
| (4.8) | |||
| (4.9) | |||
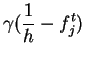 |
(4.10) |
Po té proběhne druhá kompetice
| (4.11) |
a vítěznému neuronu ![]() změníme váhy dle vzorce (4.7).
změníme váhy dle vzorce (4.7).
Výše uvedené algoritmy lze najít v [9]. Tam je také popsán složitější model samoorganizační sítě Kohonenova samoorganizační mapa, která vychází z Kohonenova učení. Její neurony jsou však navíc uspořádány do nějaké topologické struktury, která určuje, které neurony spolu sousedí. Učení pak probíhá podobně jako Kohonenovo učení, ale spolu s vítěznými neuronem jsou navíc posunovány i všechny neurony z vítězova okolí.
Různými modifikacemi Lloydova algoritmu a dalšími metodami se zabývá [3], spíše však z hlediska kódování. Pro určení středů RBF jednotek postačí popsané metody, poslední z nich -- Kohonenovo učení --je zřejmě nejpoužívanější.