Posloupnost všech parametrů sítě
| (5.3) | |||
Nejjednodušším typem funkční ekvivalence je tzv. záměnná ekvivalence, t.j. permutace skrytých jednotek (permutace sčítanců sumy). V [9] je uveden důkaz věty, která říká, že každé dvě funkčně ekvivalentní RBF sítě s Gaussovou funkcí a metrikou indukovanou skalárním součinem jsou záměnně ekvivalentní.
Parametrizaci
![]() nazveme kanonickou,
jestliže platí
nazveme kanonickou,
jestliže platí
Nyní potřebujeme upravit náš genetický algoritmus tak, aby hledal řešení pouze mezi kanonickými reprezentacemi.
Kód jedince zůstává stejný jako v části 5.2, ale navíc platí, že
![]() pro
pro
![]() . Proto musíme při vytváření počáteční
populace generovat pouze jedince reprezentující kanonické parametrizace.
. Proto musíme při vytváření počáteční
populace generovat pouze jedince reprezentující kanonické parametrizace.
Dále musíme upravit genetické operátory, které vytvářejí nové jedince.
Křížením z 5.2 otce
![]() a matky
a matky
![]() vzniknou dva noví jedinci
vzniknou dva noví jedinci
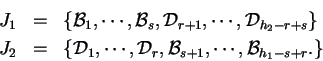
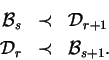
Mutace uvedená v části 5.2 vybere náhodně jeden blok ![]() a jeho
hodnotu náhodně změní. Kanonická mutace pracuje stejně, jen náhodná změna
probíhá v mezích daných sousedními bloky
a jeho
hodnotu náhodně změní. Kanonická mutace pracuje stejně, jen náhodná změna
probíhá v mezích daných sousedními bloky
![]() a
a
![]() . T.j. hodnotu bloku
. T.j. hodnotu bloku ![]() nahradíme hodnotou
nahradíme hodnotou
![]() , pro kterou platí
, pro kterou platí
![]() .
.
Takto upravený genetický algoritmus pracuje nad ![]() původního parametrického
prostoru a dá se tedy očekávat, že řešení nalezne dříve.
původního parametrického
prostoru a dá se tedy očekávat, že řešení nalezne dříve.