Třetí metodou použitou na aproximaci funkce ![]() byly genetické
algoritmy.
byly genetické
algoritmy.
Použili jsme populaci 50 jedinců a pustili jsme pětkrát klasický algoritmus a pětkrát kanonický algoritmus. Do elity byli v obou případech vybíráni dva nejlepší jedinci. Všichni jedinci měli stejnou délku, 16 jednotek.
Oba výpočty jsme nechali běžet 5 000 generací, průměrný čas potřebný na 100 generací byl v obou případech 38.45 s.
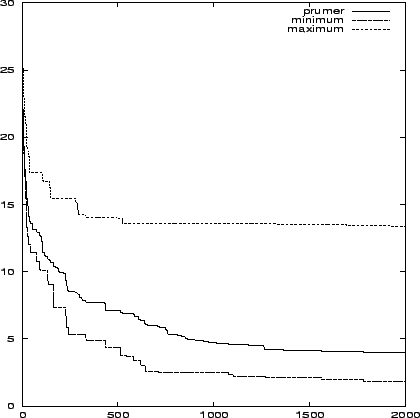
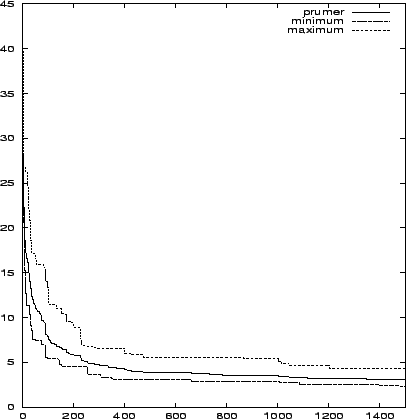
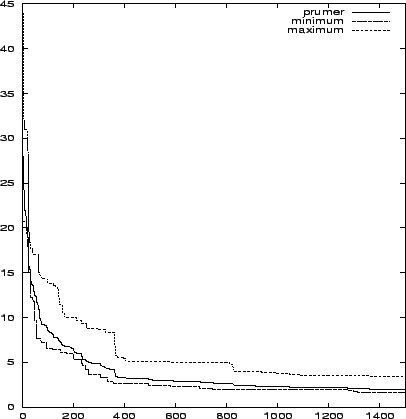
Na obrázcích 7.17 a 7.18 je vidět průběh minima, maxima a průměru chybové funkce v závislosti na generaci. Srovnání průměrného výpočtu kanonického a klasického algoritmu je pak na obrázku 7.19, kde vidíme, že kanonický výpočet si vedl o něco lépe.
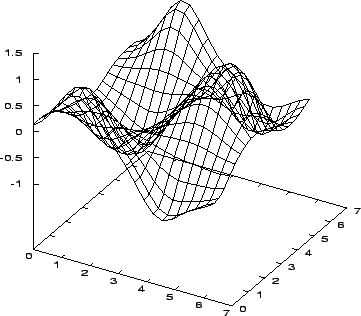
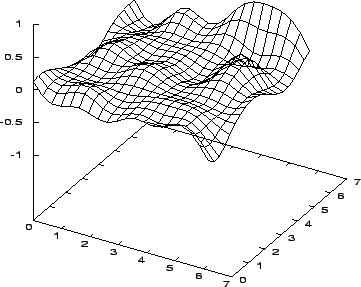
Funkce sítě naučené kanonickým genetickým algoritmem je na obrázku 7.20, obrázek 7.21 znázorňuje průběh její chybové funkce.
 |
 |
|
| |||||||||||||||||||||||||||||||||||||||||||||||||
Dalších pět výpočtů jsme provedli s kanonickým algoritmem s proměnlivou délkou jedince. Výpočet běžel 5 000 generací a průměr výsledných chyb je 3.655. Minimální dosažená chyba byla 1.4947 a maximální 13.3641. Tyto hodnoty už jsou přijatelné.
Průměrný čas na výpočet 100 generací je 8.34 s, je však závislý na délce jedinců v dané populaci, proto se během výpočtu mění.
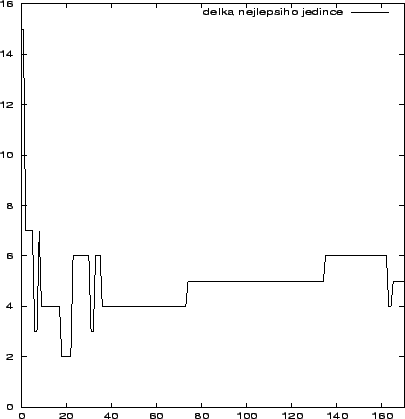
Průběh chybové funkce je znázorněn na obrázku 7.22. Na obrázku 7.23 pak vidíme jak se mění délka nejlepšího jedince v průběhu výpočtu. Na začátku výpočtu jsou sítě v populaci spíše náhodné a menší sítě mají spíše menší hodnotu chybové funkce. Proto délka nejdříve prudce klesne na malé hodnoty. Během výpočtu se pak pomalu prosazují i delší jedinci, ale nárůst délky je velice pozvolný.
|