Experimenty byly provedeny na Linuxovém clusteru Joyce v Ústavu informatiky Akademie věd. Výpočty probíhaly na jednotlivých uzlech s procesory Celeron 533 MHz a pamětí 384 MB.
Pro účely experimentů jsme zvolili úlohy různých velikostí tréninkové množiny i sítě. Řešili jsme jak problém aproximace funkce, tak problém klasifikace.
Optimální počty RBF jednotek pro danou úlohu se liší v závislosti na použité metodě. Abychom však měli možnost srovnání, učíme vždy všemi metodami stejně velké sítě.
Termínem chyba sítě v následujících kapitolách rozumíme hodnotu chybové
funkce
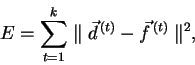
Každému experimentu odpovídá jedna kapitola, která je navíc rozdělena do podkapitol popisujících použití gradientního učení, třífázového učení a genetických algoritmů. Nakonec vždy tyto rozdílné přístupy porovnáme na základě hodnot chybové funkce a časové náročnosti.